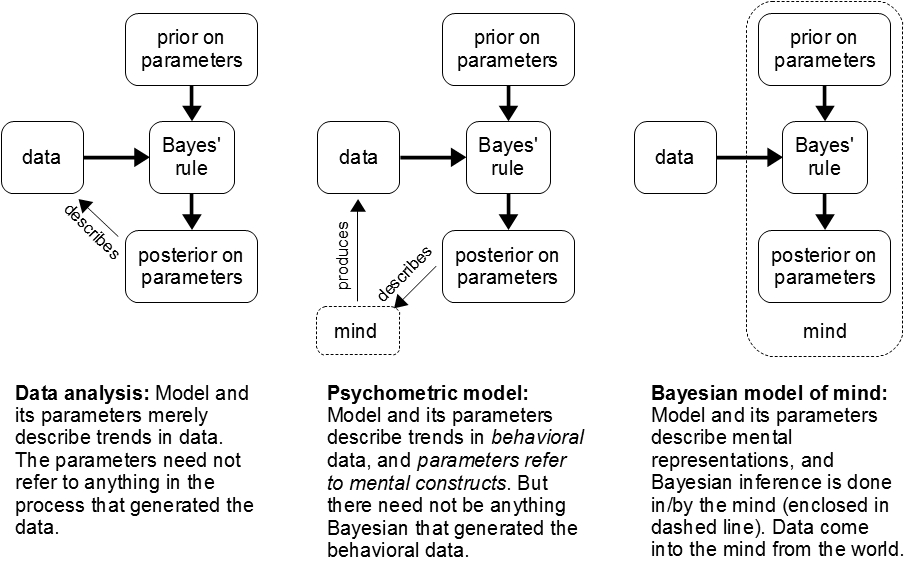
As an example of a generic data-analytic model, consider data about ice cream sales and sleeve lengths, measured at different times of year. A linear regression model might show a negative slope for the line that describes a trend in the scatter of points. But the slope does not necessarily describe anything in the processes that generated the ice cream sales and sleeve lengths.
As an example of a psychometric model, consider multidimensional scaling (MDS). The data are similarity ratings (or confusion matrices) from a human observer, and the parameters are coordinates of items in a geometric representation of mental constructs that produced the ratings. Note that if the MDS model is applied to non-behavioral data, such as inter-city road distances, then it is not a psychometric model.
As an example of a Bayesian model of mind, consider models of visual perception of concavity. The data are the light beams reflecting off the curved object in the world and falling on the retina. The model in the mind has parameters that represent the shape of the object in the world being viewed and the angle of the light falling on it. The prior has strong bias for light falling from above (e.g., from the sun and sky). The posterior estimate of shape and lighting then tends to produce interpretations of shapes consistent with overhead lighting, unless there is strong evidence to the contrary. Notice that the parameter values are inside the head, so there must be additional assumptions regarding how to measure those parameter values.
But why not go further.
ReplyDeleteThe probability that if someone smiles at you in the street, you are Barack Obama versus the probability that if you are Barack Obama someone will smile at you in the street.
Seems like a trivial example, until you spend some time doing work with people who suffer psychoses.
I wonder if this offers a profitable model?
Threat perception is also apparently soft-wired and impacted upon by things like urbanicity. Could you model psychotic thinking as a failure (more of a failure than normal) of our intuition about conditional probability.
Dear Anonymous October 27, 2011 5:22 AM:
ReplyDeleteThanks for your comment.
First, just to clarify the post itself, the purpose of the post was merely to differentiate the three applications of Bayesian parameter estimation, not to endorse Bayesian models of mind. In fact, I'm agnostic when it comes to Bayesian models of mind. It would be intellectually very interesting if theorists can create Bayesian models of mind that accurately capture human behavior, but I wouldn't be heartbroken if they couldn't. Bayesian analysis of data, however, is useful and appropriate regardless of whether Bayesian models of mind are useful.
Now, on to your comment. Your comment is getting at the larger issue: IF we use Bayesian models of mind, then how do we account for individual differences, and specifically, for abnormal/irrational behavior? Your comment suggests one answer, namely, differing degrees of fidelity to Bayes' rule. Another possibility is that behavior of all types can be construed as obeying Bayes' rule but on different model structures. From this perspective, different behaviors might all be using Bayes' rule accurately, but based on different priors and likelihood functions.
Prof. Kruschke,
ReplyDeleteDisclaimer: I'm not an expert in philosophy of science, so I may be talking nonsense.
Some people are actually reluctant to accept Bayesian models of cognition. You won't be surprised if I tell you about this aura of criticism. In my opinion, complex computations and Maths are the main issue here. It's hard to discuss seriously on what one barely understands (and most psychologists have this problem). But, in addition, I think that some researchers championing Bayesian models are just too enthusiastic and feeding a sort of Bayesian hype. Nowadays it seems as if anything could be explained by a simple probability equation! This is not that obvious for most of us, psychologists.
I was wondering, maybe the point is that Bayesian models of cognition are usually (if not always) defined at a computational level. As far as I know, this reveals no commitment to psychological processes or mechanisms. Rather, they are bounded to physical, task-based and environmental constraints. In addition, they are not actual explanations, but more like definitions. For instance, if I wished to make a computational model of how people choose a shampoo, I would take those variables of interest, examine the task to decide what the starting point and the goals are (e.g., spending little money, maintaining a luxurious hair), etc. Then I would be able to describe how optimal inference leads from point A to point B. That's information entering the system, being transformed, and yielding an optimal output.
Then, of course, people display a wide variety of behaviors, which often are far from optimal. I wouldn't be surprised, for computational models merely *describe* optimal, yet bounded, behaviors (given a starting point, a goal, a task, certain constraints, etc.). It is the role of algorithmic models to *explain*, that is, to find a mechanism that sensibly accounts for (part of) the variance in behavior. These lower-level models are of course constraint by the computational level, as well as by the even-lower neurological/physiological level. In fact, sometimes the algorithmic models are just approximations to the computational description. That is, I don't think people actually engage in the very complex computations Bayesian models include, but it's likely that the output of our cognitive system may yield a functional approximation of such computational descriptions (a connectionist network may be defined, at a computational level, as a problem of Bayesian inference with a clearly defined goal). Hence, models settled in the computational level are very useful to further constrain those other modelers postulating lower-level mechanisms. The goal, the resources, the task demands... they are all defined at the computational level, ready to be used in the algorithmic level. But the explanation lies in the lower-than-computational level.
Then, the main problem does not concern those wise modelers that stay at the computational level and merely describe behavior and set the environmental constraints. The problem concerns some "greedy" Bayesian modelers who too often put the computational description (i.e., no mechanism involved) and the postulated mechanism at the same level, as if they were competing theories, as if both were intended to explain behavior. Too often I see how the "optimality" or "rationality" assumption is reformulated once and again to account for irrational behavior. If the definition of rationality is that flexible, what's its usefulness after all?
As I said, I'm not very acquainted with philosophy of science. All these thoughts may be pure nonsense. I would be glad to have your opinion, even if you think that, well, I'm just utterly wrong. That's the only way I can learn, so don't hesitate! :-)
Fernando:
ReplyDeleteThanks very much for posting your comment.
Bayesian models of mind are, as you say, considered to be at the "computational" level instead of at the "algorithmic" or "implementational" levels. The issue of how the mind/brain might actually compute Bayesian inference is a challenging one, and has been the topic of much discussion. For example, the journal Trends in Cognitive Sciences recently had a pair of articles from proponents of Bayesian and connectionist models of mind, highlighting the complementary strengths and weaknesses of the two approaches. The pair of articles had a few accompanying commentaries, including one I wrote about how the levels might be bridged; see http://www.indiana.edu/~kruschke/articles/Kruschke2010TiCScommentary.pdf.
I think one of the intellectual triumphs of the new Bayesian approach to modeling mind is that it helps us realize that a huge spectrum of possible behaviors is "rational" or "optimal" according to different models. Behavior that seems "irrational" under one description might be exactly Bayesian under a different model description. I do not think that this flexibility makes the Bayesian approach bad; instead, if it successfully accounts for puzzling behaviors, it can be quite enlightening. The enlightenment comes from explaining behavior as genuinely Bayesian inference on some (insightfully discovered) representation. My complaint (mentioned in the article linked above) with some of the attempts to bridge computational and algorithmic levels is that human behavior can only be captured with poor approximations to the Bayesian model, which means that the human behavior is not Bayesian after all, and the wind is taken out of the sails.
I want to reiterate a remark from my previous comment in this thread: "I'm agnostic when it comes to Bayesian models of mind. It would be intellectually very interesting if theorists can create Bayesian models of mind that accurately capture human behavior, but I wouldn't be heartbroken if they couldn't. Bayesian analysis of data, however, is useful and appropriate regardless of whether Bayesian models of mind are useful." This theme is emphasized in another article in TiCS: http://www.indiana.edu/~kruschke/articles/Kruschke2010TiCS.pdf.
Prof Kruschke,
ReplyDeleteThank you very much for your reply and references. As far as I understand, some commentaries on the target papers (TICS) pinpoint some thoughts I myself was considering (but they do in a way more informed and eloquent way!).
Unfortunately, I'm just not ready for a proper discussion on this point, still need a lot of reading on the topic! So thanks for your references.
Finally, I do agree with your final remark on the independent nature of Bayesian data analysis. You already convinced me of this! :-)
Greetings,
Fernando
Professor - I was just introduced to Bayesian inference via an article in Nautilus magazine. For some reason, it struck me as an interesting way to understand how humor works - the predictive part of our minds expecting a story to go one way, and the expert comedian or humorist using those assumptions to provide a twist - a piece of data that falls outside of our predictive sampling - that delights us and makes us laugh. Do you know of any books or articles about the Bayesian mind that might help me develop this thought? Thank you so much!
ReplyDeleteInteresting question! A quick online search revealed this:
DeleteEVE′ s energy in aesthetic experience: a Bayesian basis for haiku humour. K Burns, Journal of Mathematics and the Arts, 2012, Taylor & Francis.
And here are related articles:
https://scholar.google.com/scholar?oe=utf-8&um=1&ie=UTF-8&lr&q=related:KO3KNtMoXvRuBM:scholar.google.com/