Imagine generating random data from the null hypothesis, for a fixed duration. Data appear randomly through time. Thus, for a given duration, there is a certain probability that N=4, that N=5, that N=6, and so on. For any fixed N, the sampling probability of t is given by the conventional t density. To derive the t distribution for sampling for a fixed duration, we simply add the t distributions for each possible N, weighted by the probability of getting N. That's easy to do mechanically in a computer program. All we have to do is specify p(N) for each N.
As a concrete example, suppose we have data with N=8 in each of two groups. We might have gotten those data when intending to stop at N=8 in each group, that is, N=16 altogether. Then the probability of N looks like the left panel below, with a "spike" at N=16, and the probability of getting extreme t values from the null hypothesis is shown in the right panel below, with the critical value as in the conventional tables:

But what if the data collection involved posting a sign-up sheet for a fixed duration, so that the number of volunteers is a random value, and, moreover, the actual data is collected in a room that seats a maximum of 16 people. Then the probability distribution across sample sizes might look like the left panel below, with the resulting t distribution on the right:
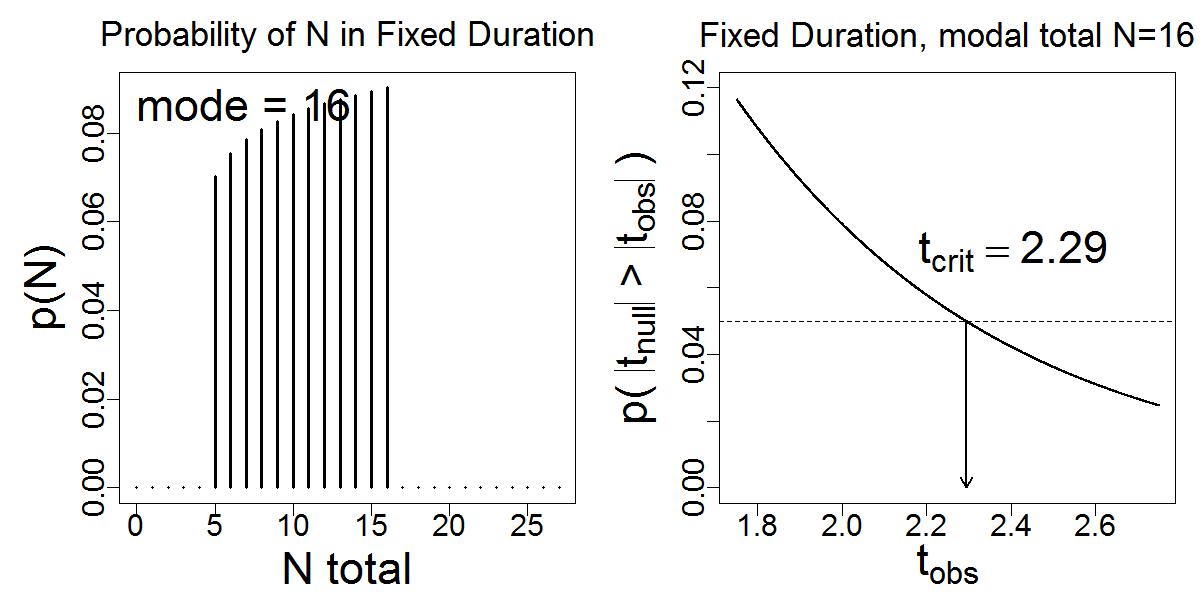
And what if data collection involved posting a sign-up sheet for a fixed duration, but the data-collection session is not run unless at least 16 people sign up? Then the probability distribution across sample sizes might look like the left panel below, with the resulting t distribution on the right:

Here's the problem: Suppose we are given some data, with N=16 and tobs=2.14. What is the p value? It depends on the stopping intention assumed by analyst, even though the stopping intention has no influence on the values in the data.
Here's the R program for generating the plots above:
# TsamplingUntilThresholdDuration.R
graphics.off()
rm(list=ls(all=TRUE))
fileNameRoot = "TsamplingUntilThresholdDuration"
# Specify the probability of getting each candidate sample size N during the
# fixed duration:
# Nprob is relative probability of getting each N, from 0 to length(Nprob)-1:
NprobSelection = c("LowSkew","Spike","HighSkew")[1] # type 1, 2, or 3 inside []
if ( NprobSelection=="LowSkew" ) {
Nprob = c(0,0,0,0,0,1,2,3,4,5,6,7,8,9,10,11,12, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
Nprob = Nprob^0.1
}
if ( NprobSelection=="Spike" ) {
Nprob = c(0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0, 0,12, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
}
if ( NprobSelection=="HighSkew" ) {
Nprob = c(0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0, 0,12,11,10, 9, 8, 7, 6, 5, 4, 3, 2, 1)
Nprob = Nprob^0.1
}
Nposs = 0:(length(Nprob)-1) # vector of N values for components of Nprob
# Outlaw getting less than 4 total (2 per group):
Nprob[1:4]=0
Nprob = Nprob/sum(Nprob) # normalize so it's a true probability distribution
# Prepare plotting parameters:
windows(width=10,height=5)
layout( matrix(1:2,ncol=2) )
cexLab = 2.25
cexMain = 1.75
cexAxis = 1.5
cexText = 2.25
marPar = c(4,5,3,1)
mgpPar = c(2.5,0.5,0)
par(mar=marPar,mgp=mgpPar)
# Plot the probability of each N:
plot( Nposs , Nprob , type="h" , lwd=3 ,
xlab="N total" , ylab="p(N)" ,
main=bquote("Probability of N in Fixed Duration"*"") ,
cex.lab=cexLab , cex.main = cexMain , cex.axis=cexAxis )
text( 0 , max(Nprob) , paste("mode =",Nposs[which.max(Nprob)]) , adj=c(0,1) ,
cex=cexText )
# Compute cumulative t distribution:
tObs = seq(1.75,2.75,length=2001) # vector of observed t values for x axis.
pAnyTgtTobs = rep(0,length(tObs)) # prob any null t greater than observed t.
for ( n in 4:length(Nposs) ) { # start at 4 because df=(n-2) and Nposs[4] is 3.
pAnyTgtTobs = pAnyTgtTobs + Nprob[n] * 2 * ( 1 - pt( tObs , df=(n-2) ) )
}
critVal = min( tObs[ pAnyTgtTobs <= .05 ] )
# Plot the cumulative t distribution:
#windows(width=7,height=7)
yLim = c(0,0.12)
textHt = 0.065
plot( tObs , pAnyTgtTobs , ylim=yLim ,
xlab=bquote(t[obs]) ,
ylab=bquote("p( "*abs( t[null] )*" > "*abs( t[obs] )*" )") ,
cex.lab=cexLab , cex.main = cexMain , cex.axis=cexAxis ,
main=bquote( "Fixed Duration, modal total N="* .(Nposs[which.max(Nprob)]) ) ,
type="l" , lwd=2 )
abline( h = 0.05 , lty="dashed" )
text( 0 , 0.05 , "p=.05" , adj=c(0.25,-0.3) )
arrows( critVal , 0.05 , critVal , 0 , length=.1 , lwd=2.0 )
text( critVal , textHt ,
bquote( t[crit] == .(signif(critVal,3)) ) , adj=c(.25,0) , cex=cexText )
plotFileName = paste(fileNameRoot,sep="")
savePlot(paste(plotFileName,NprobSelection,sep=""),type="eps")
savePlot(paste(plotFileName,NprobSelection,sep=""),type="jpg")
No comments:
Post a Comment