|
| Frequency histograms of star ratings from 30 movies (shown as pink bars). Posterior predictions of an ordered-probit model are shown by blue dots with blue vertical segments indicating the 95% HDIs. |
Usually people analyze rating data as if the data were metric, that is, people pretend that 1 star is 1.0 on a metric scale, and 2 stars is 2.0 on the metric scale, and 3 stars is 3.0, and so forth. But this is not appropriate because all we know about the star ratings is their order, not their interval separation. The ordinal data should instead be described with an ordinal model. For more background, see Chapter 23 of DBDA2E, and this manuscript.
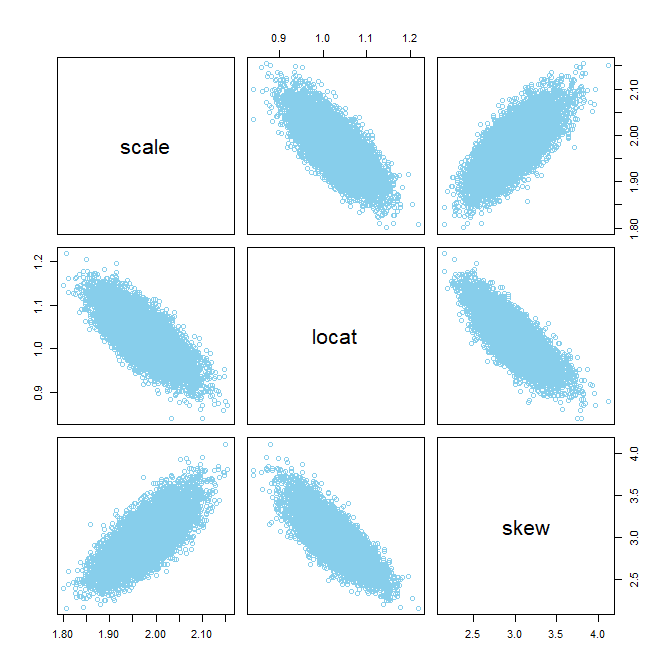
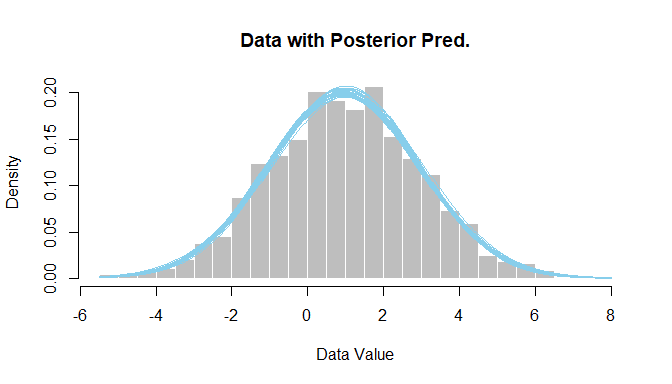
Here I used an ordered-probit model to describe the data from the 30 movies. I assumed the same response thresholds across the movies because the response scale is presented to everyone the same way, for all movies; this is a typical assumption. Each movie was given its own latent mean (mu) and standard deviation (sigma). I put no hierarchical structure on the means, as I didn't want the means of small-N movies to be badly shrunken toward enormous-N movies. But I did put hierarchical structure on the standard deviations, because I wanted some constraint on the sigma's of movies that show extreme ceiling effects in their data; it turns out the sigma's were estimated to vary quite a lot anyway.
Below is a graph of the resulting latent means (mu's) of the movies plotted against the means of their ordinal ratings treated as metric:
 |
| Each point is a movie. Vertical axis is posterior mean (mu) of ordered probit model, with 95% HDI displayed as blue segment. Horizontal axis is mean of the star ratings treated as metric values. |
Two movies with nearly equal ordinal-as-metric means, but with very different latent means in the ordered-probit model:
 |
| Upper row shows ordered-probit fit; lower row shows t test with unequal variances. Notice the blue dots from the ordered-probit model fit the data much better than the blue normal distributions of the ordinal-as-metric model. (Case 19 is Ekaterina: The rise of Catherine the Great, and Case 26 is John Grisham's The Rainmaker.) |
Two movies with ordinal-as-metric means that are significantly different in one direction but the latent means in the ordered-probit model are quite different in the opposite direction:
 |
| Upper row shows ordered-probit fit; lower row shows t test with unequal variances. Notice the blue dots from the ordered-probit model fit the data much better than the blue normal distributions of the ordinal-as-metric model. (Case 10 is Miss Sloane, and Case 26 is John Grisham's The Rainmaker.) |
This isn't (only) about movies: The point is that ordinal data from any source should not be treated as metric. Pretending that a rating of "1" is numeric 1.0, and rating "2" is 2.0, and rating "3" is 3.0, and so forth, is usually nonsensical because it's assuming metric information in the data that simply is not there. Treating the data as normally-distributed metric values is often a terrible description of the data. Instead, use an ordinal model for ordinal data. The ordinal model will describe the data better, and sometimes yield rather different implications than the ordinal-as-metric description.
For more information, see Chapter 23 of DBDA2E, and this manuscript titled, "Analyzing ordinal data with metric models: What could possibly go wrong?"